

Omics data analysis using deep learning-based framework in differential diagnosis of ovarian cancer
Iurova M.V., Tokareva A.O., Chagovets V.V., Starodubtseva N.L., Frankevich V.E.
Relevance: The course of malignant epithelial ovarian tumors is considered to be highly aggressive. Limitations of diagnostic methods are associated with the late detection of tumors at stages III–IV, which is the cause with high mortality.
Objective: To compare the effectiveness of machine learning (ML) methods for minimally invasive diagnosis of early-stage ovarian cancer (OC) using scalable, objective lipid biomarker profile data.
Materials and methods: A single-center observational retrospective cohort clinical study included 239 patients with early-stage high-grade ovarian cancer (HGOC, n=10); with other tumor/proliferative processes (n=203, of which: including 30 cystadenomas, 59 endometrioid cysts, 21 teratomas, 28 borderline tumors; 16 – low-grade ovarian cancer (LSOC), HGOC of III-IV stages and control group women (n=26). Lipid extraction, analysis by high-performance liquid chromatography coupled with electrospray ionization mass spectrometry, and data preprocessing were performed. The SHAP method was used to interpret the predictions generated by building complex models. For multi-class classification, 7 ML methods were tested, including Naive Bayes classification, PLS discriminant analysis, Random Forest, External Gradient Boosting classification, Multilayer Percepton, and Convolutional Network. For binary classification, the following were additionally tested: support vector machine and extreme gradient boosting (Xgboos) classifications.
Results: In Stages I–II HGOC, a decrease in PC O-18:1/18:0, PE P-18:0/18:2, LPC O-16:0, PC 18:0_18:2, OxTG 16:0_18:1_16:1(CHO), OxPC 18:2_16:1(COOH), OxPC 20:4_14:0(COOH) and an increase in PC 16:0_18:0, PC P-18:1/20:4, PC 18:1_18:2, PC 16:0_18:0, PC 18:2_18:2 (compared to the control group) occurred, as well as a decrease in Cer-NS d18:1/22:0, PC P-16:0/18:1, PC P-18:1/20:4, PC P-18:0/18:1, oxidized lipids, carboxy- and carbohydroxy-derivatized and an increase in PC P-18:0/18:2, PC P-20:0/20:4 (compared to patients with OC). The best differentiation ability between the control group and the OC group was demonstrated by OPLS models, as well as random forest, and support vector machine with a radial kernel (90%).
Conclusion: The use of advanced ML methods strengthens the diagnostic potential of omics data and can be applied in gynecological oncology.
Authors’ contributions: Iurova M.V. – study concept, material collection, obtaining funding, project administration, data verification, resource search, supervision, manuscript conduction, literature review, initial draft and editing; Tokareva A.O. – data control, methodology, providing software, resource search, manuscript conduction and editing; Chagovets V.V. – formal analysis, methodology, software providing; Starodubtseva N.L. – methodology, formal analysis, study concept, supervision, manuscript conduction and editing; Frankevich V.E. – formal analysis, supervision, manuscript conduction, review and editing.
Conflicts of interest: The authors declare that the study was conducted in the absence of any commercial or financial relationship that could be interpreted as a potential conflict of interest.
Funding: The study was carried out as part of the Russian Science Foundation (RSF) Grant by agreement dated December 29, 2023 No. 24-25-00407 on the "New approaches to the application of artificial intelligence for the differential diagnosis of benign and malignant ovarian tumors based on the features of the blood metabolome detected using physical methods".
Ethical Approval: The study was approved by the Commission on the Ethics of Biomedical Research of the Kulakov National Medical Research Center for Obstetrics, Gynecology and Perinatology (Protocol No.10 dated December 5, 2019). The study was initiated after the approval and was carried out in accordance with the Federal Law of the Russian Federation dated July 27, 2006 No.152-FZ (as amended on July 29, 2017) "On Personal Data," the Federal Law of the Russian Federation dated November 21, 2011 No.323-FZ "On the Basics of Health Protection in the Russian Federation" (Article 13 "Confidentiality"), the provisions of the Helsinki Declaration with all subsequent additions and amendments regulating scientific research on human biomaterials, as well as the International ethical guidelines for biomedical research involving human subjects of the Council of International Organizations of Medical Sciences (CIOMS).
Patient Consent for Publication: All patients provided informed consent for the publication of their data.
Authors' Data Sharing Statement: The data supporting the findings of this study are available on request from the corresponding author after approval from the principal investigator.
For citation: Iurova M.V., Tokareva A.O., Chagovets V.V., Starodubtseva N.L., Frankevich V.E.
Omics data analysis using deep learning-based framework in differential diagnosis of ovarian cancer.
Akusherstvo i Ginekologiya/Obstetrics and Gynecology. 2025; (10): 117-127 (in Russian)
https://dx.doi.org/10.18565/aig.2025.222
Keywords
artificial intelligence
lipidome
machine learning
metabolome
ovarian tumor
ovarian cancer
Ovarian cancer (OC) is a malignant epithelial tumor with a high mortality rate due to the biological characteristics of the disease and the lack of highly accurate diagnostic methods in the early stages of oncogenesis. According to the binary classification system invasive cancer can be divided into two types. Type I tumors are low-grade malignancies; some of them (endometrioid, mucinous, and clear cell types) contain mutations in the BRAF, KRAS, and PTEN genes with microsatellite instability, which are characterized by a less aggressive, more latent course and are less invasive. These tumors can be diagnosed at earlier stages of the disease (stages I–II). Type II tumors, in contrast, include high-grade serous ovarian cancer (HGSOC), carcinosarcoma, and undifferentiated carcinomas, which are characterized by aggressiveness, high genetic instability, and are most often diagnosed at late stages (stages III–IV). They are associated with high levels of mutations in the TP53 gene, somatic and germline BRCA1/2 mutations, and other homozygous mutations of recombinant genes [1].
Proper management of patients with ovarian neoplasms is based on a correct diagnosis. The deep location in the pelvic cavity (difficult access in small tumors), oncological (tumor dissemination) and surgical risks associated with invasive examinations (risk of injury to adjacent organs during a transabdominal procedure), epidemiological data (low incidence in the general female population, in general, and in young women interested in childbirth, in particular), as well as economic and other factors limit the routine use of histological examination. Imaging techniques such as positron emission tomography and computed tomography are highly accurate in diagnosing ovarian cancer, but their widespread use is limited by their cost and adverse physical effects [2]. Non-invasive blood tests using tumor markers such as cancer antigen 125 (CA-125) or human epididymal protein 4 (HE4) are a preferred alternative, but they show limited effectiveness in detecting OC at an early stage [3, 4]. To achieve this goal, various biomarkers for the identification of OC were discovered, including nectin-4, CCL20, Adam17, sialic acids, autoantibodies to PDLIM1, and ciRS-7 [3]. Furthermore, combination tests for multiple biomarkers or even new data analysis methods have been proposed as a potential solution to overcome the limitations of using a single marker; in particular, machine learning (ML) and deep learning are increasingly being used in the OC diagnosis. However, these technologies have not yet been widely implemented in clinical practice due to the lack of proven efficacy and insufficient validation in a wide range of cases.
Liquid biopsy is a non-invasive method for early detection of cancer based on the analysis of tumor-associated components released into various biological fluids (blood serum/plasma, urine, cervical/vaginal samples, lavage fluid from various organs and cavities), such as circulating tumor DNA, circulating tumor cells, cell-free RNA, proteins and metabolites. Growing evidence demonstrates the potential of liquid biopsy for early cancer diagnosis [5, 6]. Advances in molecular biology have led to technological innovations in genomic, transcriptomic, proteomic, and metabolomic analysis, leading to the discovery of numerous new biomarkers [1].
This study focuses on the changes in the plasma lipid profile in various ovarian diseases, identifying the possibility of using the method for differential diagnosis and improving this method using machine learning technologies in data processing and interpretation of prognostic models.
The aim of this study was to compare the effectiveness of ML technologies to improve preoperative risk assessment for early-stage ovarian cancer based on the use of scalable, objective, and minimally invasive plasma lipid biomarkers.
Materials and methods
Study design
A single-center, observational, retrospective study was conducted at the V.I. Kulakov National Medical Research Center for Obstetrics, Gynecology and Perinatology, Ministry of Health of Russia. Blood plasma samples were obtained during the period of 2019–2021 preoperatively upon receiving the informed consent by patients. Inclusion criteria: aged over 18, histological verification of diagnosis (patients with early-stage HGOC, n=10); with other tumor/proliferative processes (n=203, of which 30 women had cystadenoma, 59 had endometrioid cysts, 21 had teratoma, 28 had borderline tumor; 16 patients had low-grade epithelial malignant ovarian neoplasms (LGOC), 49 patients had stage III–IV ovarian cancer). We followed the recommendations of the International Federation of Gynecology and Obstetrics (FIGO) for the diagnosis and staging of ovarian cancer [7].
Non-inclusion criteria: aged under 18, intake of hormonal drugs for 6 months or less before the blood test, history of oncological diseases (any location other than those specified in the inclusion criteria), previous surgeries on the pelvic organs, a combination of different histotypes of neoplasms in one patient, pregnancy, diagnosed renal and/or liver dysfunction.
Exclusion criteria: data from the review of glass slides on the histotype of malignant ovarian tumors that differs from those listed in the inclusion criteria, including the detection of primary multiple tumors.
The sample size for the control group and the group with stage I–II OC was estimated based on the level of phosphatidylcholine PC 18:2_18:2 as a marker lipid for malignant processes, based on the cutoff values of the Student's t-test of 0.05 and the power of the test of 0.80. The control group consisted of 26 women who were thoroughly interviewed and pre-screened (pelvic ultrasound, clinical and biochemical blood test results, CA-125 and HE4 markers, and ROMA and RMI indices were calculated) and who met the inclusion, non-inclusion, and exclusion criteria. Biomaterials were processed and stored in the laboratory for the collection and storage of biological materials at the Kulakov National Medical Research Center for Obstetrics, Gynecology, and Perinatology, Ministry of Health of Russia.
Blood plasma lipidome analysis (HPLC-MS)
Lipid extraction, high-performance liquid chromatography-electrospray ionization mass spectrometry (HPLC-MS) analysis, and data preprocessing were performed according to methods described in previous studies [4].
Statistical analysis
Descriptive statistics were used to present the data: median (Me) and interquartile range (Q1, Q3) for continuous variables, and number and percentage for categorical variables. Three-group comparisons for continuous variables were performed using the Kruskal–Wallis and Dunn tests, while two-group comparisons were conducted with the Mann–Whitney test. Categorical parameters were compared using the Pearson chi-square test followed by a post hoc test. Differences in all cases turned out to be statistically significant at p<0.05.
Data obtained in positive and negative ion modes were combined into a single dataset. The lipidomic signatures were tested for correlation with each other using the Pearson test: if the correlation coefficient was ≥0.9, the lipid signature with the lower intensity level was excluded from the dataset. Given the imbalance of the data sets (1:20:2.6), 42 samples with stages I–II OC were added using the method of synthetic data generation at a safe level [8]. For training and testing the model, the modified data set was split in a ratio of 70% / 30%. The training set was then used to train the models, and to train the binary model, samples that did not belong to either of the two groups were removed from the set. The lipid set was identical for all models constructed; the testing set was used to evaluate the quality of the models: accuracy, model completeness, sensitivity, specificity, and calculation of the area under the curve during ROC analysis. To assess the quality of the binary model, samples that did not belong to either of the two classes discriminated by the model were temporarily removed from the testing set. The entire training dataset was used to assess the quality of the complex classifier using an ensemble of binary models.
In this study we utilized both binary and multiclass classification methods. The key difference between binary and multiclass classification is the number of target categories: binary classification divides objects strictly into two classes (e.g., diseased/healthy), while multiclass classification simultaneously distinguishes between three or more categories (e.g., control group/ovarian tumors/malignant neoplasms).
For binary classification, 11 methods of the ML algorithm were tested with the prediction of the accuracy and stability of the models: naive Bayes classification (to identify the independence of features from each other for a given class), OPLS (Orthogonal Projection Latent Structures – discriminant analysis based on orthogonal projections onto latent structures [9]), random forest (to classify problems, as a result of combining decision trees into ensembles with subsequent selection of the optimal result), support vector machine (Support Vector Machine, SVM – to divide complex data by a hyperplane for accurate classification and optimization of data processing, including unbalanced data) with a linear, polynomial, radial or sigmoid kernel, extreme gradient boosting (eXtreme Gradient Boosting, Xgboost – a form of ensemble learning based on the concept of gradient boosting and creating a reliable model for solving regression, classification and ranking), multilayer perceptron (Multilayer Perceptron, MLP – a class of artificial neural networks of direct propagation, consisting of at least three layers. When applying the method, one back-propagation algorithm trains all layers; the method is used as a classifier, since classification can be considered a special case of regression when the output variable is categorical) and a convolutional network (Convolutional Neural Network, CNN is one of the deep learning technologies, a special architecture of artificial neural networks). For multi-class classification, seven methods were tested: naive Bayes classification, discriminant analysis based on projections onto latent structures (PLS), random forest classification, external gradient boosting classification, multilayer perceptron, and a convolutional network. For the CNN models, the data was transformed into a 2D state using DeepInsight's methodology (converting non-image data into pseudo-images for the convolutional neural network architecture) [10]. Particle swarm intelligence was used to optimize the hyperparameters of neural networks (support vector machines, extreme gradient boosting, multilayer perceptron, convolutional network, and residual convolutional network). Each convolutional neural network model included a dropout layer with a cutoff of 0.1 after a Gaussian error linear unit (GELU) activation layer. The initial learning rate in all cases was 0.01 with a decay rate of 0.5. Binary models were used to build the final model, which used a one-versus-one (OvO) architecture, in which a score equal to the accuracy of the model was added for class membership. The final classification was identified by the class with the highest score. The best models were selected based on the accuracy and completeness of the models on the test set. The quality of the binary models included in the best classifier was assessed on the test sample with calculation of sensitivity, specificity, accuracy, AUC calculated during ROC analysis, predictive significance of a positive result, predictive significance of a negative result, Pearson's chi-square test to assess the agreement of the predicted sample group with the actual group. The best models were modified by adding information on age, body mass index, CA-125, HE 4 levels, reproductive status (pre- or postmenopause) and family history.
The SHAP (SHapley Additive exPlanations) method, based on cooperative game theory, was used to assess the contribution of features to diagnosis, to analyze and evaluate the properties of each group. Shapley values were calculated to identify compounds that made the greatest contribution to separating groups. These values describe the individual influence of predictors on the model and their ability to determine the object's belonging to a particular class [11] for compounds in each of the models that best separated the corresponding groups. Positive Shapley values are associated with confirmation of membership in a particular class, while negative values are associated with denial of such membership. The greatest contribution to separation was made by the combination with the highest average absolute Shapley value across the cohort.
All statistical calculations were performed using scripts in the R 4.3.3 programming language.
Results
The study included 239 patients. The clinical characteristics of the groups are presented in Table 1. The groups were compared by a number of clinical and laboratory indicators, including age, body mass index (p=0.22), menopausal status (p=0.38). The value of the CA-125 indicator was significantly lower in the control group than in the other two groups (p<0.001). The HE-4 value differed significantly between all groups, in ascending order in the series "control group – other tumor lesions – early cancer" (pC-EC=0.005, pC-T <0.001, pT-EC<0.001).

Changes in the lipid profile in ovarian cancer
We described the lipid profiles in OC plasma samples of various stages (I–II and III–IV) and grades of malignancy (high grade, low grade, borderline ovarian tumors), as well as in benign tumors (cystadenoma, teratoma, endometrioid cyst (not a true tumor, but a tumor-like formation that is a manifestation of proliferation in widespread external genital endometriosis) using HPLC-MS. In total, metabolites belonging to various lipid classes were detected in the blood plasma: phospholipids (PC), including oxidized phospholipids (OxPC) and lysophospholipids (LPC), triglycerides (TG), ceramides (Cer), and others.
Increased levels of oxidized lipids OxPC 20:3_16:1(OO), OxPC 18:1_18:0 (1O), OxTG 20:1(OOOO)_22:2(OOOO)_22:5, phospholipids with ether bond PC O-18:1/18:2, PC O-20:0/18:1, PC P-18:0/20:4, PC P-18:1/20:4 are associated with ovarian tumor lesions, which is represented by higher Shapley values for detecting ovarian tumor that is not early OC for higher lipid levels. At the same time, ovarian tumor lesions are characterized by a low level of phospholipids with a simple ether bond PC O-22:0/18:2, PE P-18:0/18:2, LPC O-16:0, which is represented by higher Shapley values for detecting an ovarian tumor that is not early OC for higher lipid levels (Fig. 1a).

When comparing blood samples from patients with stage I–II OC and from the control group, the following was shown: early stages of the malignant process are characterized by changes in the form of a decrease in PC O-18:1/18:0, PE P-18:0/18:2, LPC O-16:0, which is expressed in an inverse relationship between lipid levels and Shapley values, and an increase in PC P-18:1/20:4, which is expressed in a direct relationship between lipid levels and Shapley values (Fig. 1b), as well as a change in the content of phosphatidylcholines (an increase in PC 18:1_18:2, PC 16:0_18:0, PC 18:2_18:2 and a decrease in PC 18:0_18:2) and oxidized lipids (a decrease in OxTG 16:0_18:1_16:1(CHO), OxPC 18:2_16:1(COOH), OxPC 20:4_14:0(COOH)).
For stages I–II of ovarian cancer, a decrease in oxidized lipids, carboxy- and carbohydroxy-derivatized, was noted, in contrast to the combined pool of all other tumor lesions associated with epoxy-derivatized oxidized lipids.
It should be noted that for LPC O-16:0, PC 18:2_18:2, PE P-18:0/18:2, PC P-18:1/20:4, the characteristic directions of level changes in tumor lesions and in early OC do not differ. At the same time, the Cer-NS d18:1/22:0 level is a marker for determining whether a tumor lesion belongs to an earlier stage of OC (a malignant process is characterized by a lower level, which is reflected in higher Shapley values for the early OC group at lower lipid levels and higher Shapley values for the group of other tumor lesions at higher lipid levels). In other tumor lesions a higher level of plasminyl phosphatidylcholines is characteristic (PC P-18:0/18:2, PC P-20:0/20:4), and for early stage ovarian cancer, a lower level is characteristic (PC P-16:0/18:1, PC P-18:1/20:4, PC P-18:0/18:1) (Fig. 1c).
Elevated PC 16:0_18:0 levels may be associated with early-stage ovarian cancer, both when compared to the control group and to the group of other tumor lesions. At the same time, PC P-18:1/20:4 levels in early-stage cancer are higher than in the control group, but lower than in the group of tumor lesions.
Comparative analysis of the effectiveness of ML methods in the differential diagnosis of ovarian neoplasms
Models based on random forest, support vector machines (linear and polynomial kernel), Xgboost, multilayer percepton and convolutional neural network have equally high discriminatory accuracy in distinguishing patients diagnosed with early stage ovarian cancer from women with benign ovarian processes (99%), as well as when comparing patients with women in the control group (95%). Moreover, the models based on OPLS, random forest, and radial kernel support vector machines demonstrated the best accuracy in separating the control group from the group with benign lesions (90%). Due to this the combined classifier based on binary random forest models achieved the best result (90%, Fig. 2a). When evaluating the average completeness value, random forest, support vector machines (linear and polynomial kernel), Xgboost, multilayer percepton, and convolutional network demonstrated the best result in distinguishing patients with early stages of ovarian cancer from patients with benign pathology and from the control group (97% for both goups). When separating control patients from patients with ovarian tumors, the highest average model completeness was obtained for the model constructed using a multilayer percepton (87%). This was the cause of the best average completeness for the combined classifier based on binary classifiers using a linear percepton (89%, Fig. 2b). In the case of a direct multi-class classifier, the best accuracy was achieved by the Xgboost model (91%), and the best average model completeness was achieved by the multi-layer percepton (88%) (Fig. 2c).
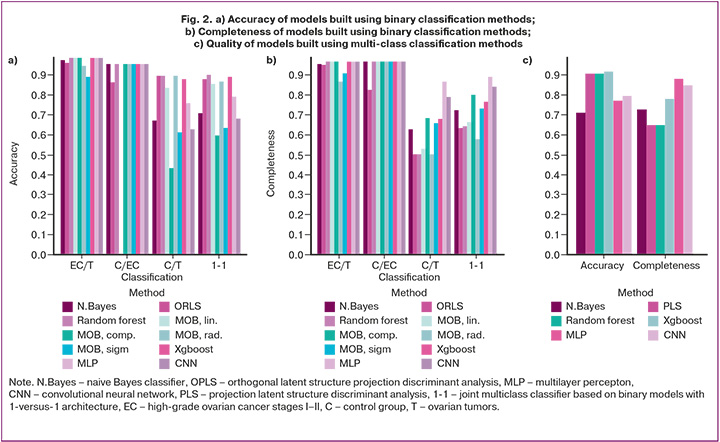
Complex binary classifiers, i.e. random forest, multilayer percepton, and direct multiclass classifiers based on Xgboost demonstrated high completeness for identifying patients with stages I–II of ovarian cancer (93%). Models using the multilayer percepton were also associated with high completeness for identifying the control group (100%). Moreover, the complex classifier using the 1-versus-1 architecture showed the best completeness for identifying women with ovarian tumors (73%) (Table 2).

The models that formed the optimal classifier had the following features (Table 3):
- Model 1 for separating samples of patients with tumor lesions and the control group consisted of 3 layers with 239, 210 and 398 nodes, respectively, and the cutoff level in each layer of dropout with the nodes layer of 0.57; the sensitivity and specificity of the model were 73% and 100%, the probability of variance of p-values<0.001.
- Model 2 for separating the control group and the group with stages I–II of ovarian cancer consisted of 2 layers with 100 and 50 nodes, respectively, and a cutoff level in each layer of dropout with the nodes layer of 0.2; the sensitivity and specificity of the model were 93% and 100%, the probability of variance of p-values<0.001.
- Model 3 for separating the group with stages I–II of ovarian cancer and the group with tumor lesions consisted of 3 layers with 30, 60, 90 nodes, respectively, and a cutoff level in each layer of dropout with the nodes layer of of 0.2; the sensitivity and specificity of the model were 93% and 100%, the probability of variance of p-values<0.001.
Modifying the models by adding information on body mass index, age, CA-125 and HE 4 levels, and menopausal status did not improve the quality of the models (Table 3).

Discussion
The lack of opportunities and conditions for routine preoperative histological verification for differential diagnosis in all patients with suspected ovarian neoplasms specifies the improvement of imaging diagnostic methods and the analysis of new options, including liquid biopsy. The most important advantages of liquid biopsy, compared to traditional tissue biopsy, are its minimal invasiveness and the possibility of multiple use during dynamic monitoring of the course of the disease at the pre-treatment stage or when monitoring the results of treatment [1]. Metabolites represent the endpoints of many biofunctional molecular processes, and disturbances at the metabolic level in blood and/or other body fluids have long been recognized as promising indicators of cancer. Metabolic profiles have been proposed as molecular phenotypes of biological systems, reflecting the combined information encoded at the genomic level, as well as transcriptomic, proteomic, and lipidomic responses. The study of the metabolic profile of blood is promising for investigating a potential diagnostic method, as well as for the search of agents involved in the main biological mechanisms of ovarian cancer [12, 13]. Fatty acid β-oxidation, amino acid catabolism, and lipid profile changes are among the processes involved in metabolic pathways associated with ovarian cancer progression. Previous metabolomic studies of ovarian cancer have primarily utilized nuclear magnetic resonance (NMR) and mass-spectrometry [1, 12]. Garcia E. et al. used NMR spectroscopy-based metabolomics to differentiate early-stage ovarian cancer patients from healthy controls, achieving an AUC of 0.949 [14]. Ke S. et al. conducted a large-scale metabolomic study of 448 plasma samples using an HPLC-MS platform [15]. Their study identified metabolic profiles and potential biomarkers that differentiate early-stage OC from ovarian tumors with AUC values of 0.91 and 0.8385, respectively.
Machine learning is a branch of artificial intelligence that has experienced significant progress in recent years, with its implementation in various areas of life. The primary goal of machine learning is to automate processes to minimize the need for human involvement in simple, routine tasks or, conversely, excessively labor-intensive work. Machine learning algorithms have become an integral part of various industries, making significant contributions to such areas as medical applications, optical character recognition, medical image processing, wireless communications, software defect prediction, and other.
We assessed the feasibility of using scalable, objective, and minimally invasive liquid biopsy-derived biomarkers, such as lipid profiles, for preoperative risk assessment of early stage (I–II) ovarian cancer in a clinically representative and diagnostically challenging population, and compared the performance of ML methods in the differential diagnosis of ovarian neoplasms. At the systemic level, multiomics approaches allow us to study oxylipins, metabolites of omega-3 or omega-6 polyunsaturated fatty acids, among other things. We compared oxylipin profiles obtained by HPLC-MS in the blood plasma of 26 healthy volunteers (control group) and 213 patients with various proliferative processes (benign tumors, malignant ovarian tumors). Previous studies have shown that the nature of changes in the content of oxidized lipids during tumor processes depends on the type of oxidant and the fatty acid undergoing oxidation [16].
According to studies published by international authors, machine learning demonstrates progressive improvement in results, achieving high accuracy in prognostic models, particularly diagnostic models. A linear support vector machine (SVM) model, consisting of 16 diagnostic metabolites, was able to identify early ovarian cancer with 100% accuracy [17]. Using recursive feature elimination (RFE) combined with repeated cross-validation (CV) based on HPLC-MS metabolomics, the developed model helped to distinguish OC cases from controls with 93% accuracy. Importantly, the overall predictive accuracy of the consensus classifier was higher for early-stage patients compared to late-stage patients [18].
The models based on multilayer perceptons for identifying patients with early-stage ovarian cancer elaborated in this work are characterized by accurate discrimination ability: the AUC for the models to separate women with early-stage cancer from women in the control group and from women with other tumor lesions was 0.97 in both cases. For comparison, according to research data, a model constructed on the basis of concentrations of free DNA and HE4 protein to distinguish blood samples from patients with early-stage OC and benign tumor lesions was characterized by the AUC of 0.76 [19]. According to Mikami M. et al., the use of a convolutional neural network trained on a glycopeptide profile to differentiate early-stage ovarian cancer from other diseases is accompanied by an improvement in the accuracy of the model: the AUC in the study was 0.92 [3]. According to the authors, the differential diagnostic model built on the basis of a set of proteins has worse sensitivity and specificity in separating ovarian tumor and early ovarian cancer (90% and 90%, respectively), but it is necessary to take into account the larger sample size in the mentioned study.
Therefore, despite the fact that the involvement of oxylipins, metabolites of polyunsaturated fatty acids, in the pathogenesis of malignant tumors has long been known, only the development and implementation of high-performance methods with integrated artificial intelligence give opportunity to study changes in the lipid profile at the systemic level with the most objective interpretation of the obtained data. The accuracy of such data determines the adoption of clinical decisions at the pre-treatment stage, which allows for the optimization of a differentiated approach to the management of patients with ovarian neoplasms.
Conclusion
We conducted a comparative study to explore if it is possible to improve the effectiveness of preoperative minimally invasive assessment of the risk of early-stage ovarian cancer using ML technologies for the analysis of scalable, objective data on the lipid biomarker profile. We also demonstrated that at the preoperative stage models based on multilayer perceptons allow to differentiate with 99% accuracy the blood profile of a patient with stages I–II OC from other tumor lesions and with 95% accuracy from patients in the control group. At the same time, it should be noted that the efficiency of the approach when using complex classifiers based on binary models was higher compared to a direct multi-class classifier. The use of advanced ML methods strengthens the diagnostic potential of omics data without appealing to variable elimination methods. Thus, since achieving better results requires the development of a personalized patient management strategy, including ovarian reserve preservation for the possibility of subsequent implementation of reproductive function, the integration of artificial intelligence into the diagnosis can improve modern minimally invasive capabilities for the detection of the disease so that it could be treated at early stages, while adhering to oncological principles and maintaining the quality of life ahead.
References
- Feng Y., Yang W., Zhu J., Wang S., Wu N., Zhao H. et al. Clinical utility of various liquid biopsy samples for the early detection of ovarian cancer: a comprehensive review. Front. Oncol. 2025; 15: 1594100. https://dx.doi.org/10.3389/fonc.2025.1594100
- Cancer Research UK. Health inequalities: breaking down barriers to cancer screening. Available at: https://news.cancerresearchuk.org/2022/09/23/health-inequalities-breaking-down-barriers-to-cancer-screening/ (accessed on August 13, 2025)
- Mikami M., Tanabe K., Imanishi T., Ikeda M., Hirasawa T., Yasaka M. et al. Comprehensive serum glycopeptide spectra analysis to identify early-stage epithelial ovarian cancer. Sci. Rep. 2024; 14(1): 20000. https://dx.doi.org/10.1038/s41598-024-70228-6
- Юрова М.В., Токарева А.О., Чаговец В.В., Стародубцева Н.Л., Франкевич В.Е. Дифференциальная диагностика злокачественных новообразований яичников на ранней стадии на основании биоинформационного исследования метаболома крови. Акушерство и гинекология. 2024; 12: 118-26. [Iurova M.V., Tokareva A.O., Chagovets V.V., Starodubtseva N.L., Frankevich V.E. Differential diagnosis of early-stage ovarian cancer based on the bioinformatic analysis of the blood metabolome. Obstetrics and Gynecology. 2024; (12): 118-26 (in Russian)]. https://dx.doi.org/10.18565/aig.2024.283
- Tokareva A., Iurova M., Starodubtseva N., Chagovets V., Novoselova A., Kukaev E. et al. Machine learning framework for ovarian cancer diagnostics using plasma lipidomics and metabolomics. Int. J. Mol. Sci. 2025; 26(14): 6630. https://dx.doi.org/10.3390/ijms26146630
- Iurova M.V., Chagovets V.V., Pavlovich S.V., Starodubtseva N.L., Khabas G.N., Chingin K.S. et al. Lipid alterations in early-stage high-grade serous ovarian cancer. Front. Mol. Biosci. 2022; 9: 770983. https://dx.doi.org/10.3389/fmolb.2022.770983
- Prat J.; FIGO Committee on Gynecologic Oncology. Staging classification for cancer of the ovary, fallopian tube, and peritoneum. Int. J. Gynaecol. Obstet. 2014; 124(1): 1-5. https://dx.doi.org/10.1016/j.ijgo.2013.10.001
- Liang D., Yi B., Cao W., Zheng Q. Exploring ensemble oversampling method for imbalanced keyword extraction learning in policy text based on three-way decisions and SMOTE. Expert Systems with Applications. 2022; 188(1): 116051. https://dx.doi.org/10.1016/j.eswa.2021.116051
- Lundberg S.M., Erion G., Chen H., DeGrave A., Prutkin J.M., Nair B. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020; 2(1): 56-67. https://dx.doi.org/10.1038/s42256-019-0138-9
- Юрова М.В., Франкевич В.Е., Павлович С.В., Чаговец В.В., Стародубцева Н.Л., Хабас Г.Н., Ашрафян Л.А., Сухих Г.Т. Диагностика серозного рака яичников высокой степени злокачественности Iа–Iс стадии по липидному профилю сыворотки крови. Гинекология. 2021; 23(4): 335-40. [Iurova M.V., Frankevich V.E., Pavlovich S.V., Chagovets V.V., Starodubtseva N.L., Khabas G.N., Ashrafyan L.A., Sukhikh G.T. Diagnosis of Ia–Ic stages of serous highgrade ovarian cancer by the lipid profile of blood serum. Gynecology. 2021; 23(4): 335-40 (in Russian)]. https://dx.doi.org/10.26442/20795696.2021.4.200911
- Sharma A., Vans E., Shigemizu D., Boroevich K.A., Tsunoda T. DeepInsight: a methodology to transform a non-image data to an image for convolution neural network architecture. Sci. Rep. 2019; 9(1): 11399. https://dx.doi.org/10.1038/s41598-019-47765-6
- Fan L., Yin M., Ke C., Ge T., Zhang G., Zhang W. et al. Use of plasma metabolomics to identify diagnostic biomarkers for early stage epithelial ovarian cancer. J. Cancer. 2016; 7(10): 1265-72. https://dx.doi.org/10.7150/jca.15074
- Li J., Wang Z., Liu W., Tan L., Yu Y., Liu D. et al. Identification of metabolic biomarkers for diagnosis of epithelial ovarian cancer using internal extraction electrospray ionization mass spectrometry (iEESI-MS). Cancer Biomark. 2023; 37(2): 67-84. https://dx.doi.org/10.3233/CBM-220250
- Garcia E., Andrews C., Hua J., Kim H.L., Sukumaran D.K., Szyperski T. et al. Diagnosis of early stage ovarian cancer by 1H NMR metabonomics of serum explored by use of a microflow NMR probe. J. Proteome Res. 2011; 10(4):1765-71. https://dx.doi.org/10.1021/pr101050d
- Ke C., Hou Y., Zhang H., Fan L., Ge T., Guo B. et al. Large-scale profiling of metabolic dysregulation in ovarian cancer. Int. J. Cancer. 2015; 136(3): 516-26. https://dx.doi.org/10.1002/ijc.29010
- Chistyakov D.V., Guryleva M.V., Stepanova E.S., Makarenkova L.M., Ptitsyna E.V., Goriainov S.V. et al. Multi-omics approach points to the importance of oxylipins metabolism in early-stage breast cancer. Cancers. 2022; 14(8): 2041. https://dx.doi.org/10.3390/cancers14082041
- Gaul D.A., Mezencev R., Long T.Q., Jones C.M., Benigno B.B., Gray A. et al. Highly-accurate metabolomic detection of early-stage ovarian cancer. Sci. Rep. 2015; 5: 16351. https://dx.doi.org/10.1038/srep16351
- Ban D., Housley S.N., Matyunina L.V., McDonald L.D., Bae-Jump V.L., Benigno B.B. et al. A personalized probabilistic approach to ovarian cancer diagnostics. Gynecol. Oncol. 2024; 182: 168-75. https://dx.doi.org/10.1016/j.ygyno.2023.12.030
- Gaillard D.H.K., Lof P., Sistermans E.A., Mokveld T., Horlings H.M., Mom C.H. et al. Evaluating the effectiveness of pre-operative diagnosis of ovarian cancer using minimally invasive liquid biopsies by combining serum human epididymis protein 4 and cell-free DNA in patients with an ovarian mass. Int. J. Gynecol. Cancer. 2024; 34(5): 713-21. https://dx.doi.org/10.1136/ijgc-2023-005073
Received 19.08.2025
Accepted 23.10.2025
About the Authors
Mariia V. Iurova, PhD, obstetrician-gynecologist, oncologist, Senior Researcher at the Scientific Polyclinic Department, V.I. Kulakov NMRC for OG&P, Ministry of Health of Russia, 117997, Russia, Moscow, Ac. Oparin str., 4, hi5melisa@gmail.com, https://orcid.org/0000-0002-0179-7635Alisa O. Tokareva, PhD (Physico-Mathematical Sciences), Specialist at the Laboratory of Clinical Proteomics, V.I. Kulakov NMRC for OG&P, Ministry of Health of Russia, 117997, Russia, Moscow, Ac. Oparin str., 4, +7(495)531-44-44 (ext. 3113), alisa.tokareva@phystech.edu, https://orcid.org/0000-0001-5918-9045
Vitaliy V. Chagovets, PhD (Physico-Mathematical Sciences), Head of the Laboratory of Metabolomics and Bioinformatics, V.I. Kulakov NMRC for OG&P, Ministry of Health of Russia, 117997, Russia, Moscow, Ac. Oparin str., 4, +7(495)438-21-98, vvchagovets@gmail.com
Natalia L. Starodubtseva, PhD (Bio), Head of the Laboratory of Clinical Proteomics, V.I. Kulakov NMRC for OG&P, Ministry of Health of Russia, 117997, Russia, Moscow,
Ac. Oparin str., 4, n_starodubtseva@oparina4.ru, https://orcid.org/0000-0001-6650-5915
Vladimir E. Frankevich, Dr. Sci. (Physico-Mathematical Sciences), Deputy Director of the Institute of Translational Medicine, V.I. Kulakov NMRC for OG&P, Ministry of Health of Russia, 117997, Russia, Moscow, Ac. Oparin str., 4, v_frankevich@oparina4.ru
Corresponding author: Mariia V. Iurova, hi5melisa@gmail.com
Similar Articles

