

Comparison of predictive models built with different machine learning techniques using the example of predicting the outcome of assisted reproductive technologies
Drapkina Yu.S., Makarova N.P., Vasiliev R.A., Amelin V.V., Kalinina E.A.
Advancements in machine learning (ML) have resulted in the development of numerous supporting software products for reproductive medicine. Predicting the performance of assisted reproductive technology (ART) using ML can be accomplished using different algorithms, depending on the type of data and specific task at hand.
Objective: This study aimed to compare the predictive ability of logistic regression, decision tree algorithm, and Random Forest in relation to the likelihood of pregnancy based on the clinical, anamnestic, and embryologic data of patients undergoing ART.
Materials and methods: This retrospective study included 854 married couples and analyzed clinical and laboratory data as well as parameters of the stimulated cycle in relation to the effectiveness of the ART program using three ML algorithms: logistic regression, decision tree, and Random Forest.
Results: The most accurate algorithm for predicting pregnancy rates in the ART program was the Random Forest model, which identified the significance of the following predictors: embryonic arrest, triggering of final oocyte maturation, number of embryos of excellent and average quality, duration of stimulation, infertility factor, body mass index, FSH, and AMH levels. The model confirmed the significance of the predictors determined in the previous stages of the study using a decision tree algorithm, including the presence/absence of a history of previous pregnancies, parameters of the stimulated cycle (number of MII oocytes), spermogram indicators on the day of the puncture, number of embryos of excellent and good quality, and quality of the embryo according to morphological evaluation criteria.
Conclusion: To enhance the prediction of ART effectiveness, this study suggests the need for better mathematical models with an integrated approach to solve the problem using a large sample of patients with various input data presented in a balanced volume. Additionally, this study suggests the inclusion of additional markers that determine ART effectiveness, thereby improving the accuracy of the software product.
Authors’ contributions: Drapkina Yu.S., Makarova N.P., Kalinina E.A. – conception and design of the study; Drapkina Yu.S. – data collection and analysis; Amelin V.V., Vasiliev R.A. – statistical analysis; Drapkina Yu.S., Amelin V.V., Vasiliev R.A. – drafting of the manuscript; Kalinina E.A., Makarova N.P. – editing of the manuscript.
Conflicts of interest: The authors have no conflicts of interest to declare.
Funding: There was no funding for this study.
Ethical Approval: The study was reviewed and approved by the Research Ethics Committee of the V.I. Kulakov NMRC for OG&P.
Patient Consent for Publication: All patients provided informed consent for the publication of their data.
Authors’ Data Sharing Statement: The data supporting the findings of this study are available upon request from the corresponding author after approval from the principal investigator.
For citation: Drapkina Yu.S., Makarova N.P., Vasiliev R.A., Amelin V.V., Kalinina E.A. Comparison of predictive models built with different machine learning techniques using the example of predicting the outcome of assisted reproductive technologies.
Akusherstvo i Ginekologiya/Obstetrics and Gynecology. 2024; (2): 97-105 (in Russian)
https://dx.doi.org/10.18565/aig.2023.263
Keywords
artificial intelligence
assisted reproductive technology (ART)
reproductive medicine
machine learning
decision support system
Random Forest
ART effectiveness
pregnancy rate
The development of the Russian healthcare system relies heavily on the use of modern technologies. There is increasing focus on leveraging various mathematical algorithms to enhance the quality of medical care [1, 2]. Artificial intelligence (AI), specifically machine learning (ML), plays a crucial role in this field. ML aims to develop algorithms that can utilize input data to predict output information as new data become available. It is important to note that ML goes beyond statistical methods as it involves constructing learning-based algorithms without an explicit solution form [3].
ML is extensively utilized in various medical fields, including its implementation in assisted reproductive technology (ART). In the field of reproductive medicine, the development of ML has led to the development of many supporting software products [4]. Currently, there is a notable emphasis on developing programs to predict the effectiveness of ART and optimize treatment methods [5]. However, erroneous and inaccurate predictions can hinder the timely targeting of treatment methods for married couples, impact patient expectations regarding pregnancy frequency, and impede the appropriate allocation of funds from the Compulsory Health Insurance Fund (CHI) [6]. Consequently, predicting the effectiveness of ART programs is a top priority when developing a software product.
The prediction of ART program performance using ML can be achieved through various algorithms depending on the data type and specific task at hand. The main ML methods used in reproductive medicine include logistic regression, decision tree algorithms, and random forests [7].
Logistic regression
Logistic regression addresses the classification problem by determining the probability that a given input value belongs to a particular class. If the source data points satisfy this requirement, they are deemed linearly separable (Figure 1) [8].
Additionally, the further a point is from the dividing surface, the higher is the chance that it belongs to this class.
Decision Tree Algorithm
The decision tree algorithm divides a dataset into smaller subsets based on their characteristics. The essence of this method is that the decision tree repeatedly divides the data until only one class remains. The Gini impurity criterion was used when constructing a decision tree [9].
When choosing to divide a node according to a certain characteristic, the Gini criterion reflects the extent to which this division reduces the uncertainty in the data [10].
Random Forest algorithm
It is worth noting that one decision tree tends to overfit for a specific training sample; therefore, in practice, a composition of decision trees (Random Forest) should be used. The Random Forest algorithm is based on the use of several decision trees. They demonstrate the logic by which the researcher makes decisions. Optimizing decision trees for a specific problem involves enumerating the features and partition thresholds to determine the best partition. The tree changes greatly when the sample changes; therefore, to build various trees from a sample of length M, subsets of the same length M are selected and returned, and trees are built on these subsets. This approach is known as bootstrapping. In a regression problem, the results obtained by “many” trees are averaged; in a classification problem, the decision is made by majority voting. In addition, when constructing a tree, one cannot go through all the features, but choose from a random subset q. Trees can be built in parallel because the constructions do not depend on each other [11].
Although numerous studies have been published on the development of ML-based predictive models for ART outcomes, there are a limited number of studies comparing different ML algorithms and evaluating the performance of each model because of technical limitations, such as difficulties in determining cause-and-effect relationships between the data obtained during ML, and the need to use a large amount of data to build models using various algorithms.
This study aimed to compare the predictive ability of logistic regression, decision tree algorithm, and random forest in relation to pregnancy rates based on clinical, anamnestic, and embryological data of a cohort of patients undergoing infertility treatment using ART.
Materials and methods
The first phase of this study was conducted in collaboration with specialists in the field of ML and AI to build a decision tree algorithm to determine the most significant predictors of clinical pregnancy in ART programs [12]. Among these predictors, the maximum contribution to the pregnancy rate was determined by the following parameters: the presence/absence of a history of pregnancies, parameters of the stimulated cycle (number of oocyte-cumulus complexes (OCC), M II oocytes, zygotes), spermogram indicators on the day of puncture, number of embryos of excellent and good quality, as well as the quality of the embryo (size of the embryo, state of the internal cell mass, and trophectoderm cells).
The tree was built by partitioning the data into subsets based on feature values for classification using the Python system, determining the robustness of the data and testing the resulting data on a test set using the Scikit-learn library. The Gini impurity criterion was used to construct a decision tree. This criterion measures the uncertainty or “purity” of a set of elements by assessing the probability of misclassification of a randomly selected element in the set [12].
This study analyzed the accuracy of models built using a decision tree algorithm, logistic regression, and Random Forest. The study retrospectively included 854 married couples aged 21–44 years who sought ART infertility treatment. Written voluntary informed consent was obtained from each participant for the processing of personal data.
The criteria for inclusion in the study were: infertility caused by tubo-peritoneal, male, or combined factors; chronic anovulation or reduced ovarian reserve, as well as the presence of a normal karyotype of the spouses; ovarian stimulation according to the protocol with gonadotropin-releasing hormone antagonist (GnRH-antagonists) (GnRH antagonist); standard protocol for post-transfer period support; obtaining oocytes on the day of transvaginal puncture (TVP); and transfer of one embryo.
Exclusion criteria were abnormalities in the structure of the uterus, karyotype abnormalities, and the use of donor oocytes or sperm.
All patients enrolled in the study were divided into 5 groups according to their age: group 1 (n=100) – 21–24 years old; group 2 (n=195) – 25–29 years old; group 3 (n=220) – 30–34 years old; group 4 (n=256) – 35–39 years old; and group 5 (n=83) – 40–44 years old.
Patients included in the study underwent ovarian stimulation according to the GnRH antagonist protocol from the 2nd or 3rd day of the menstrual cycle. Upon reaching a follicle diameter of ≥17 mm, patients were prescribed a trigger for final oocyte maturation, the human chorionic gonadotropin (hCG) (n=600) or, in case of a risk of ovarian hyperstimulation syndrome, the trigger was replaced with a GnRH agonist (n=171), or a double trigger for final oocyte maturation was administered (n=83). After TVP, which was performed 35–36 hours after ovulation induction, oocytes were retrieved, and their quality was assessed. Fertilization of the resulting oocytes was performed by in vitro fertilization (IVF) in 5.6%, intracytoplasmic sperm injection into the oocyte (ICSI) in 81.9%, and physiological ICSI (PICSI) in 12.5% of the cases. All cultivation stages were carried out in multi-gas incubators SOOK (Ireland) in 25 μl drops under oil (Irvine Sc., USA) in the B.V. Leonov Department of Assisted Technologies for the Treatment of Infertility. On the 5th day after fertilization, the embryo was transferred into the uterine cavity using a soft Wallace (Germany) or Cook (Australia) catheter. The remaining embryos, suitable for further use in cryopreserved transfers, were cryopreserved. Support for the luteal phase and further management of the post-transfer period were carried out according to standard generally accepted methods. On day 14 after embryo transfer, β-human chorionic gonadotropin (β-hCG) levels were assessed. If the β-hCG result was positive, patients underwent a pelvic ultrasound examination 21 days after the transfer to diagnose a clinical pregnancy. The rest of the pregnancies were managed individually.
The study also analyzed the embryological parameters of the stimulated cycle, including spermogram indicators on the TVP day (sperm concentration, percentage of progressively motile spermatozoa, percentage of non-progressive, immobile spermatozoa, percentage of morphologically healthy spermatozoa), number of OCC, mature MII oocytes, number of fertilized oocytes (zygotes), quality of the embryo (size of the embryo, state of the internal cell mass, and trophectoderm cells), number of blastocysts of excellent, good, and average quality, as well as the number of embryos with development arrest on days 2–3 after fertilization. In addition, the clinical pregnancy rates were analyzed.
Statistical analysis and algorithm for building ML models
The study analyzed 51 specific variables divided into three groups:
- Binary variables that take only two values (e.g., the number of previous IVF programs)
- Categorical: discrete variables that take one of a finite number of values and indicate that an object belongs to a certain category (for example, the quality of an embryo according to morphological evaluation criteria);
- Substantiative: values of a feature from a real set (for example, the concentration of sperm in the ejaculate).
For the binary variables, the values are replaced by {0, 1}. For the logistic regression model, all substantiative variables were normalized, and categorical variables were encoded using One-Hot Encoding technology; N new variables were created for the encoded categorical feature, where N is the number of categories. Each new i-th feature is a binary characteristic feature of the i-th category [13]. One-Hot Encoding is one of the methods of transforming data to prepare it for the algorithm and obtain a better prediction. One-Hot Encoding converts each categorical value into a new categorical column and assigns a binary value of 1 or 0 to these columns. For logistic regression, decision tree, and random forest models, all categorical features were encoded using One-Hot Encoding.
The distribution of the outcome variable (clinical pregnancy) among all the participants in this study is shown in Figure 2.
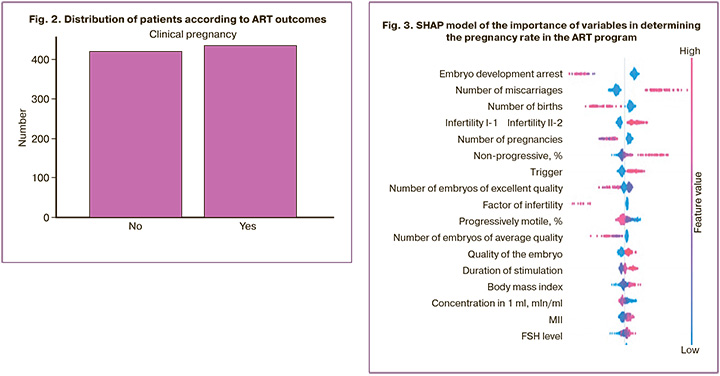
“YES (clinical pregnancy +)” – 435 entries;
“NO (clinical pregnancy -)” – 419 entries.
Before the modeling stage, the analyzed sample was randomly divided into training and testing sets in relation to training (70%) and testing (30%).
The following algorithms were considered for modeling:
- Logistic regression;
- Decision tree;
- Random Forest.
To analyze the model quality metrics, the precision and recall criteria were introduced. Precision can be interpreted as the proportion of objects called positive by the classifier and actually being positive, and recall shows the proportion of objects of the positive class out of all objects of the positive class that the algorithm found.
Results
The quality metrics listed in Table 1 were used to compare the effectiveness of the models.
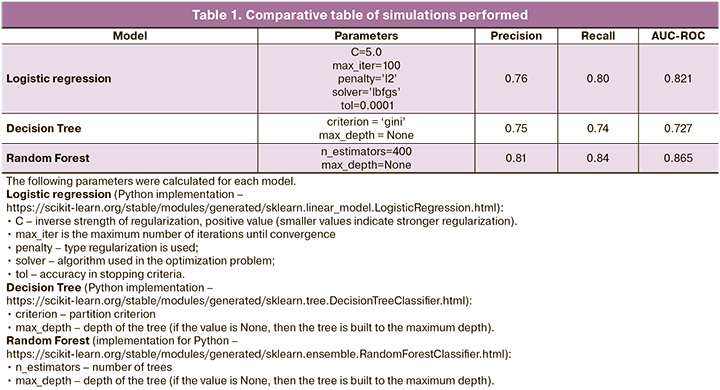
According to Table 1 and the results of quality metric analysis, the Random Forest model demonstrated the best results.
The SHAP library was used to interpret the importance of each indicator in the final prediction of the model, the SHAP (SHapley Additive exPlanations) library as shown in Figure 3. To assess the importance of the indicators, Shapley values were calculated, which made it possible to identify all possible combinations and options, and after analyzing the data, determine which factors are actually important when choosing. To assess the importance of the indicator, the predictions of the model “with” and “without” this indicator were assessed.
To correctly analyze the graph, it should be noted that each point is a separate observation, and the higher the sign on the Y-axis, the more important it is in relation to the pregnancy rate (Fig. 3). The values to the left of the central vertical line are negative class (0), those to the right are positive (1), and the thicker the line on the graph, the greater the number of observation points. The values of the corresponding attributes are displayed in color: the higher the attribute, the redder it is displayed; the lower the attribute, the bluer it is displayed.
Thus, the resulting model identified “additional” significant factors that are important in determining the effectiveness of the ART program: embryo development arrest, trigger of final oocyte maturation, number of embryos of excellent and average quality, duration of stimulation, infertility factors, body mass index, FSH, and AMH levels. In addition, the significance of the predictors that were determined at the previous stages of the work was also confirmed using the decision tree algorithm using Random Forest: the presence/absence of a history of pregnancies, parameters of the stimulated cycle (number of MII oocytes), spermogram indicators on the day of puncture, the number of embryos of excellent and good quality, as well as the quality of the embryo according to morphological criteria (embryo size, state of the internal cell mass, and trophectoderm cells).
Discussion
Automatic learning algorithms are gradually becoming an integral part of modern science [14].
In this study, three ML algorithms were analyzed: logistic regression, Decision Tree and Random Forest. Some of the most effective models currently used to solve classification problems are based on the Random Forest (RF) algorithm. They account for more than 70% of all the developed models. Random Forest is one of the most common approaches for solving classification problems, and is a compositional method that generates a set of different classification models to achieve better accuracy. The basic classification algorithm, with which all developed models are always compared, is logistic regression. Its features include ease of implementation, speed of operation, and interpretability of the results (logistic regression estimates the probability of an event occurring and interprets the results based on the importance of each attribute). Considering that the resulting quality metrics of precision and recall were maximum for the Random Forest model, the implementation of this particular algorithm was chosen during the analysis.
Another widely used ML algorithm is the artificial neural network. However, based on the size of the training dataset and type of data collected, the use of neural networks in this case is inappropriate because a larger sample size is required to build a high-quality model using neural networks. To solve the problem of classifying features using a given volume of input parameters, the three most suitable and optimal models for solving this problem have been proposed [15].
Logistic regression is a method for constructing a linear classifier that allows the estimation of the probabilities of assigning objects to one of the two classes. Logistic regression uses a linear combination of input features and corresponding weights that describe a linear hyperplane in the feature space. This result is then passed through a logistic function that converts the linear combination into the probability of an object belonging to one of the classes [8].
Advantages:
- This is a relatively simple algorithm that requires a small amount of computing resources.
- Interpretability: Logistic regression provides an understanding of which variables have an impact on classification and how.
- Enables high model accuracy with small data sets.
Defects:
- Requires feature normalization to ensure that features contribute equally to the model.
- When solving problems with a large number of features or a complex data structure, the accuracy of the resulting model decreases.
- May have low accuracy when classes are not linearly separable.
This algorithm was interesting, first of all, because of the possibility of interpreting the results, as well as testing the hypothesis of linear separability of classes; however, it showed poor quality in practice, confirming more complex structure in the training data. The model implementation for Python from the scikit-learn library was used (https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html).
It is worth noting that a decision tree is a hierarchical tree structure and helps in solving classification and regression problems. Unlike neural networks, a decision tree as an analytical model is simpler because the rules are generated by generalizing training examples that describe the domain. Small changes in the data can lead to significant changes in the tree structure, making the model unstable.
A universal ML algorithm can be the Random Forest model, the essence of which is to use an ensemble of decision trees. The decision tree itself provides extremely low classification quality, but due to the large number of them, the result improves significantly [9].
The results showed that the maximum precision and recall values were obtained for the model using the Random Forest algorithm. A model built using Random Forest showed that the presence/absence of a history of pregnancy/number of miscarriages/births, as well as the quality of the embryo and the number of embryos that development arrest on days 2–3 after fertilization have the maximum impact on the effectiveness of the IVF. In addition, the pregnancy rate is influenced by the trigger of the final maturation of oocytes, the duration of stimulation, the number of blastocysts of average and excellent quality, spermogram indicators on the day of puncture, as well as the number of MII oocytes.
A study published in 2022 built a model for predicting pregnancy rates using ML. The study included 24,730 couples undergoing IVF/ICSI infertility treatment. The algorithm was trained using the Random Forest model and logistic regression. The study identified the variables that most influence the prognosis of treatment, among which the most significant contribution was made by the ovarian stimulation protocol, and Random Forest proved to be the most promising as an ML method [16].
The findings are consistent with those of other researches who have found that infertility factor and semen on the day of TVP should also be included in the model for calculating the probability of pregnancy. According Vaegter K.K. et al., among the most informative indicators for assessing the quality of ejaculate, sperm concentration, motility and ejaculate volume should be highlighted. It is worth noting that research to determine the most significant indicator for assessing the quality of ejaculate to optimize a man’s preparation for the ART program and assess the effectiveness of the treatment appears promising [17].
The presence/absence of a history of pregnancy is another significant predictor of pregnancy in the ART program, according to the constructed predictive models. According to a study by Tarín J.J. et al., the infertility factor, the presence/absence of a history of pregnancy, as well as the patient’s age are the predictive factors for pregnancy in the ART program. It is worth emphasizing that in this study, the age of the couple did not show a significant effect on the pregnancy rate in the ART program, perhaps due to the fact that using ML, the most significant predictive factors were discovered that were directly dependent on age [18].
Compared to logistic regression, ML algorithms are more sensitive and more accurate methods for which the limitations of traditional regression are less applicable. In reproductive medicine, ML algorithms are widely used to determine the most significant predictive markers of pregnancy in the ART program. Yang H. et al. analyzed the factors influencing the pregnancy rate in the IVF program and subsequently built a prognostic model. The case-control study included data from 369 women undergoing ART infertility treatment. Univariate and multivariate logistic regression and Random Forest model analyzes were performed to identify potential predictors. The importance of variables was shown according to the mean reduction of the Gini criterion. According to the data obtained, the maximum contribution to the effectiveness of the ART program is made by age, body mass index, number of previous IVF attempts, hematocrit, LH, progesterone levels, endometrial thickness, and FSH level. The results obtained allow us to identify groups of patients at high risk of negative treatment outcomes in the ART program and promptly provide adequate preparation and treatment [19].
Thus, the results obtained reflect the need for further study of the influence of certain factors on pregnancy rates. The construction of more accurate prognostic systems using a larger sample size, as well as additional mathematical approaches, will not only increase the pregnancy rate by optimizing correctable factors, but also identify the most promising group of patients for the appropriate allocation of the mandatory health insurance budget for financing IVF programs. It is worth noting that it seems promising to analyze the resulting sample using the gradient boosting algorithm, which can largely mitigate the shortcomings of the Random Forest model and provides more accurate results. In addition, the use of unique non-invasive biomarkers in the mathematical model for assessing the quality of the embryo using the analysis of the blastocyst culture medium allows increasing the predictive accuracy of the algorithm [20]. In this study, more than 500 samples of follicular fluid, seminal plasma, sperm and embryo culture medium were collected from patients undergoing ART according to an integrated biological sample storage system [21].
Conclusion
Currently, models based on regression analysis have shown an accuracy rate of no more than 70%. To enhance the precision of predicting the effectiveness of the ART program, it is essential to develop improved algorithms that adopt a comprehensive approach to addressing the issue, along with the identification of molecular markers that can enhance diagnostic accuracy. Expanding the training sample and constructing individual predictive models using more precise mathematical approaches will help in minimizing the number of potential clinical and anamnestic predictors of pregnancy rates in the ART program. This, in turn, will lead to the creation of a more user-friendly and convenient software product. Future scientific research will be dedicated to this crucial task.
References
- Ившин А.А., Багаудин Т.З., Гусев А.В. Искусственный интеллект на страже репродуктивного здоровья. Акушерство и гинекология. 2021; 5: 17-24. [Ivshin A.A., Bagaudin T.Z., Gusev A.V. Artificial intelligence on guard of reproductive health. Obstetrics and Gynecology. 2021; (5): 17-24 (in Russian)]. https://dx.doi.org/10.18565/aig.2021.5.17-24.
- Драпкина Ю.С., Калинина Е.А., Макарова Н.П., Мильчаков К.С., Франкевич В.Е. Искусственный интеллект в репродуктивной медицине: этические и клинические аспекты. Акушерство и гинекология. 2022; 11: 37-44. [Drapkina Yu.S., Kalinina E.A., Makarova N.P., Milchakov K.S., Frankevich V.E. Artificial intelligence in reproductive medicine: ethical and clinical aspects. Obstetrics and Gynecology. 2022; (11): 37-44. (in Russian)]. https://dx.doi.org/10.18565/aig.2022.11.37-44.
- Акжолов Р.К. Машинное обучение. Вестник науки. 2019; 3(6): 348-51. [Akzholov R.K. Machine learning.Vestnik Nauki. 2019; 3(6): 348-51. (in Russian)].
- Хохлов А.Л., Белоусов Д.Ю. Этические аспекты применения программного обеспечения с технологией искусственного интеллекта. Качественная клиническая практика. 2021; 1: 70-84. [Khokhlov A.L., Belousov D.Yu. Ethical aspects of using software with artificial intelligence technology. Good Clinical Practice. 2021; (1): 70-84. (in Russian)]. https://dx.doi.org/10.37489/2588-0519-2021-1-70-84.
- Сахибгареева М.В., Заозерский А.Ю. Разработка системы прогнозирования диагнозов заболеваний на основе искусственного интеллекта. Вестник РГМУ. 2017; 6: 42-6. [Sakhibgareeva M.V., Zaozersky A.Yu. Developing an artificial intelligence-based system for medical prediction. Vestnik RGMU. 2017; (6): 42-6. (in Russian)].
- Кобякова О.С., Стародубов В.И., Кадыров Ф.Н., Обухова О.В., Ендовицкая Ю.В., Базарова И.Н., Чилилов А.М. Новая система договоров в рамках ОМС. Менеджер здравоохранения. 2021; 4: 76-82. [Kobyakova O.S., Starodubov V.I., Kadyrov F.N., Obukhova O.V., Endovitskaya Yu.V., Bazarova I.N., Chililov A.M. New system of contracts within the framework of compulsory health insurance. Manager Zdravoohranenia. 2021; (4): 76-82. (in Russian)]. https://dx.doi.org/10.21045/1811-0185-2021-4-76-82.
- Barnett-Itzhaki Z., Elbaz M., Butterman R., Amar D., Amitay M., Racowsky C. et al. Machine learning vs. classic statistics for the prediction of IVF outcomes. J. Assist. Reprod. Genet. 2020; 37(10): 2405-12. https://dx.doi.org/10.1007/s10815-020-01908-1.
- Wang Q.Q., Yu S.C., Qi X., Hu Y.H., Zheng W.J., Shi J.X., Yao H.Y. Overview of logistic regression model analysis and application. Zhonghua Yu Fang Yi Xue Za Zhi. 2019; 53(9): 955-60. https://dx.doi.org/10.3760/cma.j.issn.0253-9624.2019.09.018.
- Uddin S., Khan A., Hossain M.E., Moni M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Mak. 2019; 19(1): 281. https://dx.doi.org/10.1186/s12911-019-1004-8.
- Jaworski M., Duda P., Rutkowski L., Jaworski M., Duda P., Rutkowski L. et al. New splitting criteria for decision trees in stationary data streams. IEEE Trans. Neural Netw. Learn. Syst. 2018; 29(6): 2516-29.
- Hu J., Szymczak S. A review on longitudinal data analysis with random forest. Brief. Bioinform. 2023; 24(2): bbad002. https://dx.doi.org/10.1093/bib/bbad002.
- Драпкина Ю.С., Макарова Н.П., Татаурова П.Д., Калинина Е.A. Поддержка врачебных решений с помощью глубокого машинного обучения при лечении бесплодия методами вспомогательных репродуктивных технологий. Медицинский cовет. 2023; 15: 27-37. [Drapkina J.S., Makarova N.Р., Tataurova P.D., Kalinina E.A. Deep machine learning applied to support clinical decision-making in the treatment of infertility using assisted reproductive technologies. Medical Council. 2023; (15): 27-37. (in Russian)]. https://dx.doi.org/10.21518/ms2023-368.
- Shen C., Wang Q., Priebe C.E. One-hot graph encoder embedding. IEEE Trans. Pattern Anal. Mach. Intell. 2023; 45(6): 7933-8. https://dx.doi.org/10.1109/TPAMI.2022.3225073.
- Гусев А.В. Перспективы нейронных сетей и глубокого машинного обучения в создании решений для здравоохранения. Врач и информационные технологии. 2017; 3: 92-105. [Gusev A.V. Prospects for neural networks and deep machine learning in creating health solutions. Information Technologies for the Physician. 2017; (3): 92-105. (in Russian)].
- Nayarisseri A., Khandelwal R., Tanwar P., Madhavi M., Sharma D., Thakur G. et al. Artificial intelligence, big data and machine learning approaches in precision medicine & drug discovery. Curr. Drug Targets. 2021; 22(6): 631-55. https://dx.doi.org/10.2174/1389450122999210104205732.
- Wang C.W., Kuo C.Y., Chen C.H., Hsieh Y.H., Su E.C.Y. Predicting clinical pregnancy using clinical features and machine learning algorithms in in vitro fertilization. PloS One. 2022; 17(6): e0267554. https://dx.doi.org/10.1371/journal.pone.0267554.
- Vaegter K.K., Lakic T.G., Olovsson M., Berglund L., Brodin T., Holte J. Which factors are most predictive for live birth after in vitro fertilization and intracytoplasmic sperm injection (IVF/ICSI) treatments? Analysis of 100 prospectively recorded variables in 8,400 IVF/ICSI single-embryo transfers. Fertil. Steril. 2017; 107(3): 641-648.e2. https://dx.doi.org/10.1016/j.fertnstert.2016.12.005.
- Tarín J.J., Pascual E., García-Pérez M.A., Gómez R., Hidalgo-Mora J.J., Cano A. A predictive model for women's assisted fecundity before starting the first IVF/ICSI treatment cycle. J. Assist. Reprod. Genet. 2020; 37(1): 171-80. https://dx.doi.org/10.1007/s10815-019-01642-3.
- Yang H., Liu F., Ma Y., Di M. Clinical pregnancy outcomes prediction in vitro fertilization women based on random forest prediction model: A nested case-control study. Medicine (Baltimore). 2022; 101(49): e32232. https://dx.doi.org/10.1097/MD.0000000000032232.
- Zmuidinaite R., Sharara F.I., Iles R.K. Current advancements in noninvasive profiling of the Embryo Culture Media Secretome. Int. J. Mol. Sci. 2021; 22(5): 2513. https://dx.doi.org/10.3390/ijms22052513.
- Долудин Ю.В., Драпкина Ю.С., Сазонкина П.О. Киселев А.Р., Горбунов К.С. Виртуальная система хранения биологических образцов и ассоциированных данных. Свидетельство о государственной регистрации программы для ЭВМ. Номер свидетельства: RU 2023610092. Патентное ведомство: Россия. Год публикации: 2023. Номер заявки: 2022686282. Дата регистрации: 19.12.2022. [Doludin Yu.V., Drapkina Yu.S., Sazonkina P.O. Kiselev A.R., Gorbunov K.S. Virtual storage system for biological samples and associated data. Certificate of state registration of a computer program. Certificate number: RU 2023610092. Patent Office: Russia. Year of publication: 2023. Application number: 2022686282. Registration date: 19/12/2022. (in Russian)].
Received 14.11.2023
Accepted 10.01.2024
About the Authors
Yulia S. Drapkina, PhD, Researcher at the Department of IVF named after Prof. B.V. Leonov, Academician V.I. Kulakov National Medical Research Center for Obstetrics, Gynecology and Perinatology, Ministry of Health of Russia, 117997, Russia, Moscow, Academician Oparin str., 4, yu_drapkina@oparina4.ru,https://orcid.org/0000-0002-0545-1607
Natalya P. Makarova, PhD, Leading Researcher at the Department of IVF named after Prof. B.V. Leonov, Academician V.I. Kulakov National Medical Research Center for Obstetrics, Gynecology and Perinatology, Ministry of Health of Russia, 117997, Russia, Moscow, Academician Oparin str., 4, np_makarova@oparina4.ru,
https://orcid.org/0000-0003-8922-2878
Robert A. Vasiliev, Head of the Laboratory of Applied Artificial Intelligence Z-union, Vice-President of the Association of Laboratories for the Development of Artificial Intelligence, graduate student at the Moscow Institute of Physics and Technology (MIPT), Master of the Department of Applied Physics and Mathematics of the Moscow Institute of Physics and Technology, Master of Economics, Bachelor’s degree at the Research University «Moscow Institute of Electronic Technology».
Vladislav V. Amelin, Technical Director of the Laboratory of Applied Artificial Intelligence Z-union, expert in machine learning, Master’s degree from Moscow State University (Faculty of Computational Mathematics and Cybernetics, Department of Mathematical Methods), Bachelor’s degree from the National Research University
«Moscow Institute of Electronic Technology».
Elena A. Kalinina, Dr. Med. Sci., Professor, Head of the Department of IVF named after Prof. B.V. Leonov, Academician V.I. Kulakov National Medical Research Center for Obstetrics, Gynecology and Perinatology, Ministry of Health of Russia, 117997, Russia, Moscow, Academician Oparin str., 4, e_kalinina@oparina4.ru,
https://orcid.org/0000-0002-8922-2878
Similar Articles

