
По данным исследований, бесплодием страдают около 186 млн людей по всему миру [1]. Основными причинами бесплодия у женщин являются: нарушения менструального цикла, заболевания эндокринной системы, овуляторная дисфункция, повреждения маточных труб и др. Основные факторы мужского бесплодия – аномалии сперматогенеза, генетические факторы и сосудистые заболевания. Следует отметить, что примерно в 30% случаев диагностические мероприятия безуспешны, и причина бесплодия остается неизвестной [2].
На помощь бесплодным парам пришли вспомогательные репродуктивные технологии (ВРТ), наиболее распространенной из которых является искусственное оплодотворение. Несмотря на высокую стоимость, сложную технику исполнения и достаточно невысокие показатели успешности процедуры (20–30%) [3], искусственное оплодотворение остается главным методом лечения бесплодия.
На исход оплодотворения оказывает влияние множество факторов: возраст женщины, состояние матки, количество и качество полученного биоматериала (ооцитов), морфологические характеристики спермы и др. [4]. Пожалуй, одним из главных факторов, влияющих на исход лечения, является качество эмбриона. Тщательная оценка этого параметра особенно важна для наступления беременности в самые короткие сроки [5]. В современных лабораториях оценка качества эмбриона производится вручную, посредством визуальной оценки морфологии эмбриона через оптический микроскоп. Однако у этого способа есть существенные недостатки. Во-первых, оценка субъективна, так как зависит от уровня знаний и опыта специалиста. Следовательно, сделать ее объективной, даже в пределах одной клиники затруднительно. Во-вторых, оценка не универсальна, это часто связано с тем, что в центрах применяют разные системы градации качества эмбрионов [6]. Возможность выбрать один эмбрион с наибольшим потенциалом позволила бы увеличить вероятность благоприятного исхода [7]. К тому же это позволило бы исключить риск многоплодной беременности вследствие переноса нескольких эмбрионов в матку [8].
Помимо этого, ВРТ включают в себя и другие сложные этапы профилактики, диагностики и лечения, в том числе использующие продукты цифрового здравоохранения. Одним из самых перспективных направлений развития информационных технологий является создание алгоритмов на основе анализа больших объемов данных и машинного обучения (МО). Они могут сыграть ключевую роль в развитии «системной медицины» и повышении качества оказания медицинской помощи бесплодным парам.
В статье будут рассмотрены основные принципы создания и работы алгоритмов МО в контексте ВРТ, области применения МО, а также некоторые ограничения и недостатки указанных технологий.
Введение в понятие «искусственный интеллект»
Термин «искусственный интеллект» (ИИ) впервые предложил Джон Маккарти в 1956 г., определив его как способность машин обучаться и проявлять интеллект, отличный по своим свойствам от интеллекта человека и животных. Развитие технологий ИИ происходило поэтапно, в каждом этапе были «золотые годы», а завершались они «зимами», которые характеризуются подчас завышенными ожиданиями исследователей и последующим разочарованием в силу неспособности достичь заявленных целей и пригодности для применения, особенно в клинической врачебной практике [9]. На современном этапе направление ИИ включает в себя несколько базовых технологий, таких как компьютерное зрение, обработка естественного языка (NLP) и т.п.
Основу технологий ИИ составляет МО – специальный подход к созданию интеллектуальных программ, основанный на том, что необходимый алгоритм формируется не путем программирования или создания экспертных систем, а путем автоматического результата на основе анализа компьютером подготовленных наборов данных, на которых машина «учится» давать ответ на поставленный вопрос [10]. В медицине технологии МО активно используются для создания программ автоматизации обработки медицинских данных, контроля и поиска врачебных ошибок, прогнозирования заболеваний и т.д. [11].
Основные этапы машинного обучения
1. Подготовка набора данных (рис. 1). На основе имеющейся цифровой информации из электронных медицинских карт (ЭМК), радиологических (PACS) и лабораторных систем специалисты (data scientist) формируют набор данных. Он включает в себя независимые переменные – предикторы и зависимые переменные – целевые признаки.
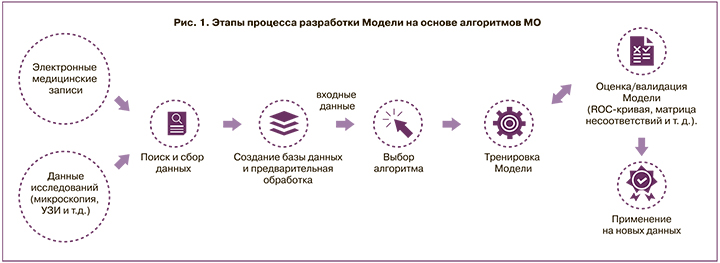
2. Для срабатывания алгоритмов МО данные размечают, выделяя в них метки патологических значений/образований или формальные признаки. Полученный набор данных разделяется на тренировочный (на его основе проводится обучение) и тестовый – для проверки правильности работы алгоритма.
3. Обучение модели. Используя специальные программные пакеты, специалист по МО применяет различные подходы и методы МО для получения наиболее точной модели. Существует несколько десятков методов МО, включая глубокое МО (Deep learning, DL).
4. Тестирование модели включает в себя оценку чувствительности, специфичности и точности. Также возможно построение кривой рабочих характеристик приемника (кривой ошибок). ROC-кривая (Receiver operating characteristic) – это график, необходимый для оценки качества бинарной классификации. Он отображает взаимосвязь между чувствительностью и специфичностью модели. Важным показателем, основанным на ROC-кривой, является AUC (Area under ROC-curve, площадь под ROC-кривой), который помогает интерпретировать график. Значение AUC демонстрирует, с какой вероятностью случайный образец данных будет верно классифицирован алгоритмом [12]. Как правило, различают внутреннее тестирование – оно проводится на тех же данных, что осуществлялись МО, и внешнюю валидацию – проверку на данных, которые не были доступны на этапе обучения.
5. Применение новых данных.
Типы машинного обучения
МО подразделяют на три главные категории: «обучение с учителем», «обучение без учителя» и «обучение с подкреплением» [10, 13].
Обучение с учителем (Supervised learning, контролируемое обучение)
Этот тип обучения широко применяется в репродуктивной медицине. Проводится тренировка модели на наборе размеченных входных данных, которые связаны с известными выходными данными. В качестве входных данных могут выступать возраст, вес, уровень гормонов пациента и другие параметры. В качестве выходных данных могут быть выбраны репродуктивные исходы. Для корректного обучения набор данных должен быть заранее обработан (размечен) человеком, что требует больших временных затрат. Однако, как только алгоритм обучится, он сможет прогнозировать исходы и при работе с новой информацией [12]. Обучение с учителем фокусируется на классификации и регрессии. В репродуктивной медицине алгоритмы на основе этого типа обучения применяются, как правило, для анализа изображений и предиктивной аналитики.
Обучение без учителя (Unsupervised learning, неконтролируемое обучение, спонтанное обучение)
В отличие от «обучения с учителем», неконтролируемое обучение не предполагает наличия заранее определенного исхода, результата, который можно было бы прогнозировать. Алгоритму требуется самостоятельно обнаружить внутренние закономерности, существующие между объектами. Это мощный инструмент для задач ассоциации и кластеризации, который часто применяют в тандеме с алгоритмами на основе контролируемого обучения.
Обучение с подкреплением (Reinforcement learning)
Обучение с подкреплением сосредоточено на постоянном повышении точности модели путем проб и ошибок. В настоящее время обучение с подкреплением в основном используется для обработки медицинских изображений [7].
Методы машинного обучения, применяемые в ВРТ
Основные методы МО, используемые в репродуктивной медицине: дерево решений (Decision tree); случайный лес (Random forest); метод опорных векторов (Support vector machine, SVM); Байесовская сеть (Bayesian network, BN); глубокое обучение (Deep learning) и сверточная нейронная сеть (Convolutional neural network, CNN); искусственная нейронная сеть (Artificial neural network, ANN) и др. [7] (рис. 2).
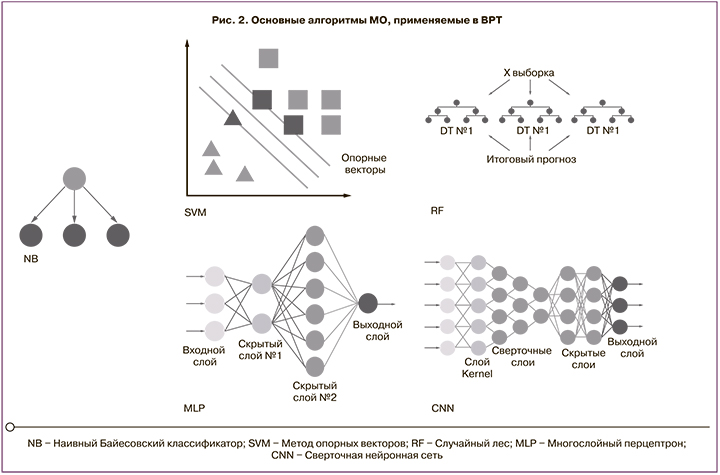
Дерево решений (Decision Tree)
По сравнению с другими, этот алгоритм проще понимать и интерпретировать. Недостаток – высокий риск «переобучения» (когда модель демонстрирует плохую работу с примерами, не задействованными в ее обучении) [7]. Дерево решений может применяться для определения эмбриона с наиболее высоким потенциалом к имплантации. Carrasco B. et al. провели исследование, в котором были отобраны 800 эмбрионов с известными данными об имплантации. Ретроспективно была проведена оценка морфологических и морфокинетических параметров эмбрионов, в результате чего была создана иерархическая модель, позволяющая с помощью вышеперечисленных параметров делать прогноз в отношении успешности имплантации эмбриона [14]. В своем исследовании Sahoo A. et al., используя алгоритмы – дерево решений, метод опорных векторов, логистическая регрессия, многослойный перцептрон (Multilayered perceptron, MLP), установили связь между некоторыми параметрами образа жизни и окружающей среды и качеством спермы человека. Было доказано, что возраст, хирургические вмешательства, употребление алкоголя, курение, аварии являются параметрами, оказывающими наиболее сильное влияние на качество спермы. Также в ходе исследования выяснилось, что предварительный отбор входных переменных увеличивает качество модели и точность срабатывания алгоритмов [15].
Случайный лес (Random Forest)
Cлучайный лес – алгоритм, состоящий из ансамбля деревьев принятия решений. Благодаря этому он корректирует риск «переобучения» деревьев принятия решений, дает более точные результаты, чем при использовании «одиночного леса». Недостаток: требует более сложной настройки модели.
Liao S. et al. разработали динамическую систему оценки бесплодия, основанную на таких параметрах пациенток, как возраст, индекс массы тела, уровень фолликулостимулирующего гормона, количество антральных фолликулов, уровень антимюллерова гормона, количество ооцитов, а также толщина эндометрия. С помощью алгоритма случайного леса был установлен вес каждого параметра. После тестирования и валидации была получена система оценки степени бесплодия, которая способна, используя вышеперечисленные параметры, отнести пациентку к одной из пяти категорий (A, B, C, D, E), упрощая процесс диагностики [16].
Группа исследователей во главе с Hafiz P. провели сравнение алгоритмов Random forest, Recursive partitioning (RPART, рекурсивное разделение), Adaptive boosting, One-nearest neighbour в контексте прогнозирования исхода искусственного оплодотворения и интрацитоплазматической инъекции сперматозоидов (ИКСИ) по 29 вариабельным параметрам. Были выбраны данные 486 пациенток. Согласно результатам исследования, Random forest и RPART превзошли остальные алгоритмы для принятия решений. Также было установлено, что возраст женщины, уровень эстрадиола в сыворотке крови в день назначения хорионического гонадотропина и количество развившихся эмбрионов являются наиболее подходящими параметрами для подобного прогнозирования [17].
Метод опорных векторов (Support Vector Machine, SVM)
Классификаторы, работающие на основе этого алгоритма, разделяют данные на два класса, используя построение одной или нескольких линейных границ – разделяющих гиперплоскостей (hyperplane) [18]. В основном данный метод применяется в задачах классификации и регрессии. Недостаток: сложность обучения модели [7]. Filho E. et al. использовали алгоритм SVM для создания полуавтоматической системы оценки жизнеспособности эмбрионов на основе морфологических особенностей бластоцист. Изображения бластоцист, полученные методом микроскопии, были сегментированы с помощью технологий обработки и анализа изображений. Были выделены такие части, как блестящая оболочка, трофэктодерма и внутренняя клеточная масса (эмбриобласт). Эти данные подверглись дальнейшей обработке, после чего были внесены в алгоритм с целью оценки жизнеспособности эмбриона по его морфологическим особенностям. Авторы убеждены, что разработанная система поможет избежать субъективной оценки, а также сделает анализ эмбрионов более точным [19].
Метод опорных векторов также может быть использован для оценки качества спермы, используемой для искусственного оплодотворения. Mirsky S. et al. предложили применять количественные фазовые карты для автоматизированной оценки спермы. Полученные путем интерферометрической фазовой микроскопии изображения сперматозоидов были подвергнуты обработке – были изолированы такие особенности строения клеток, как 3D-морфология, содержимое и параметры головок сперматозоидов. Данные в виде 378 изображений сперматозоидов от 8 доноров были использованы для тренировки классификатора, работающего на основе SVM. Авторы подчеркивают, что для получения более корректных результатов необходимо продолжить поиски подходящего алгоритма, а также использовать для тренировки более крупные массивы данных [20].
Байесовская сеть (Bayesian Network)
В приведенных ниже исследованиях использовался Наивный байесовский классификатор (Naïve Bayes classificatory). Это самый простой по устройству алгоритм из множества алгоритмов, работа которых основана на теореме Байеса. Недостаток: входные данные должны быть статистически независимы, иначе возникают проблемы с работой алгоритма. Несмотря на то что Байесовский классификатор является упрощенным классификатором, он способен справляться с такими серьезными задачами, как прогнозирование вероятности успешной имплантации эмбриона после ЭКО.
Uyar A. et al. провели ретроспективное исследование, целью которого являлось прогнозирование исхода имплантации эмбриона в результате ИКСИ. На основе информации о 2435 пересаженных эмбрионах была составлена база данных, с помощью которой провели тренировку алгоритма. В результате была получена модель, благодаря которой можно с точностью в 80,4% прогнозировать исход имплантации эмбриона при ИКСИ [21].
Таким образом, Байесовский классификатор может быть использован и в целях отбора наилучшего материала для искусственного оплодотворения, в частности – эмбрионов, как это продемонстрировано в исследовании Morales D. et al. [22]. Для того чтобы создать базу данных, была отобрана информация об эмбрионах из 63 клинических случаев и выделены переменные, определяющие, по мнению исследователей, успешность имплантации: толщина блестящей оболочки, степень фрагментации, многоядерность и размер бластомера. Помимо этого, были использованы такие параметры, как возраст, количество предыдущих циклов ЭКО, качество спермы, причина бесплодия, количество перенесенных эмбрионов, были ли заморожены эмбрионы, день переноса эмбриона и др. Далее информация была использована для тренировки нескольких типов Байесовских классификаторов, в том числе и Наивного Байесовского классификатора, который в результате продемонстрировал точность, равную 68,25%. Авторы исследования считают, что эта разработка эффективна не только в качестве системы поддержки принятия врачебных решений при лечении бесплодия, но также сможет выступить инструментом для тренировки молодых специалистов-эмбриологов [22].
Искусственная нейронная сеть (Artificial Neural Network, ANN)
Искусственные нейронные сети – это алгоритмы, которые условно имитируют нейронную сеть человеческого мозга. Принцип их работы основан на взаимодействии нейронов. В ANN их роль выполняют узлы искусственной нейронной сети, связанные между собой иерархически таким образом, что входные данные для одних узлов является выходными для других. В области ВРТ ANN может использоваться для решения задач классификации, прогноза и выбора образцов. Недостатками являются: принцип «черного ящика» (искусственные сети имеют ограниченные возможности для определения пользователем причинно-следственных связей между входными и выходными данными), значительная вычислительная нагрузка, склонность этих алгоритмов к «переобучению» [23]. El-Shafeiy et al. использовали возможности искусственных нейронных сетей, в частности – многоуровневого перцептрона (MLP) для определения качества спермы. Базу данных составили записи о 100 пациентах. В качестве переменных выступили 9 факторов образа жизни. Работу ANN дополнили другим алгоритмом – Sperm Whale Optimization algorithm (SWA, разработан на основе жизнедеятельности кита). Результат оказался многообещающим, точность анализа составила 99,96%. Исследователи считают, что это обусловлено совместным применением ANN и SWA [24].
Многослойный перцептрон (MLP), метод опорных векторов (SVM), случайный лес (RF), а также дерево решений (DT) были задействованы в исследовании Hassan M. et al. с целью прогнозирования исхода искусственного оплодотворения. Для тренировки алгоритмов использовались данные о лечении бесплодия у 1729 пациентов. В число 25 параметров для оценки прогноза вошли следующие: возраст, показание к ЭКО, метод забора спермы, толщина эндометрия, качество спермы, количество извлеченных ооцитов, прием препаратов, стимулирующих овуляцию, и др. При этом 18 показателей имели численные значения, 7 – категориальные. Точность метода MLP составила 97,77%. Наилучшие результаты были достигнуты благодаря методу опорных векторов (точность – 98,01%) и методу случайного леса (точность – 98,83%) [25].
Глубокое обучение (Deep learning) и сверточная нейронная сеть (Convolutional Neural Network, CNN)
Глубокое обучение (DL) – совокупность методов МО, основанных на обучении представлениям, а не специализированным алгоритмам под конкретные задачи. DL обычно использует нейронные сети с несколькими скрытыми слоями, и каждый слой выполняет построение объектов для слоев перед ним. По сравнению с нейронной сетью глубокое обучение может обрабатывать данные со сложными структурами, используя больше скрытых слоев [26]. В медицинских приложениях наиболее распространенными алгоритмами глубокого обучения являются сверточная нейронная сеть (CNN), рекуррентная нейронная сеть (RNN) и глубокая нейронная сеть (DCNN). CNN успешно справляется с данными больших размеров, особенно с данными, представленными в виде изображений. При их анализе CNN выступает как математический оператор, который, получив изображения и фильтр в качестве входных данных, производит отфильтрованные выходные данные. В репродуктивной медицине эта особенность сверточной нейронной сети активно используется для классификации изображений эмбрионов.
При оценке жизнеспособности эмбриона часто используется Time-lapse анализ. Технология заключается в непрерывном наблюдении за развитием эмбриона в условиях инкубатора. Устройство включает в себя микроскоп и фотокамеру, которая делает снимки эмбриона через небольшие промежутки времени. Затем снимки монтируются в фильм, и специалист оценивает по нему развитие эмбриона. Продолжительность стадий развития эмбриона коррелирует с его качеством и жизнеспособностью [27]. Для осуществления точного измерения временных параметров необходимо вручную отслеживать изменения в морфологии бластоцист. Khan A. et al. предложили автоматизировать процесс подсчета количества клеток бластоцист с изображений, полученных методом Time-lapse анализа. Информацию о 256 эмбрионах в виде необработанных 148 993 кадров Time-lapse исследования подвергли анализу. В качестве аннотации к тренировке разработанная структура использовала лишь количество клеток на изображении, не требуя таких параметров, как форма и размер клеток, их расположение. В результате был получен счетчик клеток на основе сверточной нейронной сети, точность которого достигает 87,36% [28].
Miyagi Y. et al. в своем исследовании установили возможность прогнозирования рождения ребенка у пациенток нескольких возрастных групп по данным изображений бластоцист. Была собрана информация в виде 5691 изображения бластоцист, сделанных спустя 115 (или 139) ч после инсеминации. Затем изображения были распределены по группам в зависимости от возраста пациенток. Для каждой возрастной группы разработан алгоритм на основе CNN. Параллельно данные групп проанализированы с помощью традиционной системы оценки эмбрионов (Сonventional embryo evaluation). В результате ИИ продемонстрировал более высокие суммарные показатели специфичности и чувствительности, чем традиционная система оценки [29].
Одной из наиболее часто применяемых шкал оценки эмбриона является шкала Гарднера, на основе которой можно проводить классификацию эмбрионов. Как утверждают Chen T. et al., разработка автоматизированной системы позволит снизить субъективность оценки, а также уменьшить количество времени, затрачиваемого на этот этап искусственного оплодотворения. Всего было отобрано 171 239 изображений микроскопии 16 201 эмбриона. Авторы отмечают, что это первое исследование подобного рода, в котором используются данные азиатского населения. Изображения были разделены на три группы: 60% – для тренировки CNN, 20% – для валидации, 20% – для тестирования. Использовавшийся алгоритм на основе CNN был предварительно обучен на базе данных ImageNet (проект по созданию и сопровождению массивной базы данных аннотированных изображений, предназначенный для отработки и тестирования методов распознавания образов и машинного зрения). Те же самые данные были проанализированы и отнесены к группам по шкале Гарднера тремя опытными эмбриологами. При сравнении результатов алгоритм продемонстрировал среднюю точность анализа – 75,36% [29].
Ограничения применения машинного обучения
Существуют некоторые ограничения и нерешенные проблемы применения алгоритмов МО, связанные как с технической стороной вопроса, так и с применением алгоритмов в условиях практического здравоохранения.
Например, проблемы «underfitting» (недообучение) и «overfitting» (переобучение). О переобучении уже было сказано выше. Недообучение – ситуация, при которой алгоритм не может уловить основной тренд в данных, взаимосвязи между входными и выходными данными. Причиной может стать выбор слишком простого или не вполне подходящего алгоритма [30]. Алгоритмы глубокого обучения требуют использования действительно больших баз данных для тренировки, что не всегда представляется возможным. В противном случае результаты могут быть некорректными, соответственно, вся работа над моделью окажется безрезультатной [31]. Даже если алгоритм уже создан, прошел тестирование и валидацию, перед исследователями возникает еще одна проблема – так называемая «AI Chasm» (пропасть ИИ). Под «пропастью» подразумевается тот факт, что между разработкой готового надежного алгоритма и его внедрением в работу медицинских клиник есть огромная разница. Так как модель изначально тестируется на выборке данных определенной популяции, нет гарантии того, что она успешно справится с данными выборок из других популяций или с данными другого типа [32].
Заключение
Проблема невысоких показателей успешности ЭКО особенно ярко выделяется на фоне возрастающего числа бесплодных пар. Для улучшения качества оказания медицинской помощи пациентам с бесплодием эксперты международных медицинских сообществ обращаются к помощи компьютерных технологий. Технологии ИИ, несмотря на существующие ограничения и недостатки, демонстрируют многообещающие результаты.
ВРТ являются обширным полем для изучения алгоритмов МО, поскольку эта отрасль медицины располагает не только большими базами данных (Big Data) в виде электронных медицинских записей, но и современными методами диагностики и лечения, в которые могут быть интегрированы системы классификации, прогнозирования и поддержки принятия врачебных решений, основанные на работе ИИ.
Таким образом, ВРТ становятся не просто ресурсом для развития возможностей ИИ в медицине, но и площадкой для последующего применения алгоритмов в практике врача.


